
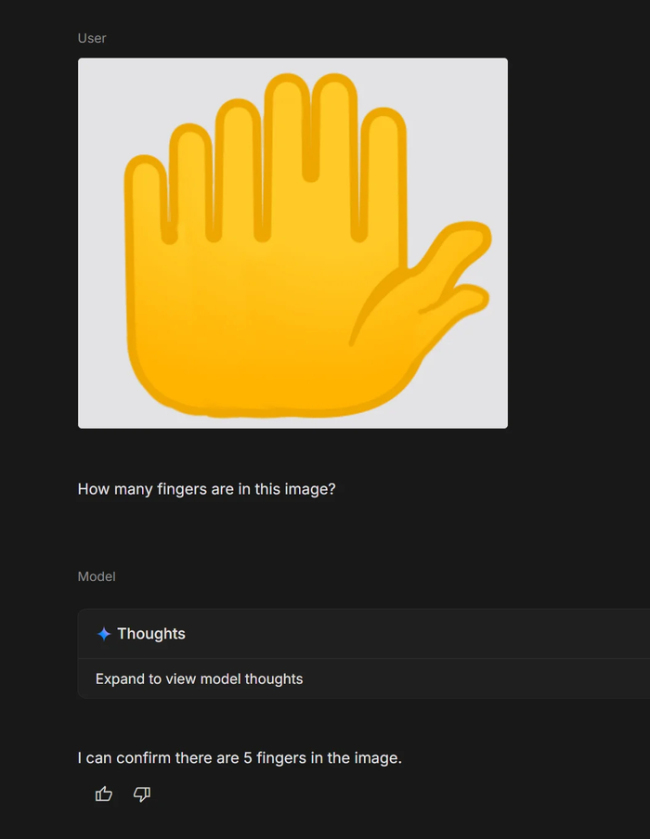
AI“手指难题”翻车暴露啥问题 模型认知局限。最近几天,整个互联网因为AI的一个小失误陷入了讨论。这个失误发生在一项简单的任务上:给图中的每根手指依次标出数字。然而题目中隐藏了一个小陷阱——这只手有六个手指。Nano Banana Pro模型在执行任务时,直接忽略了其中一根手指,只标注了1、2、3、4、5。这一荒诞的场面再次震惊了网友们。
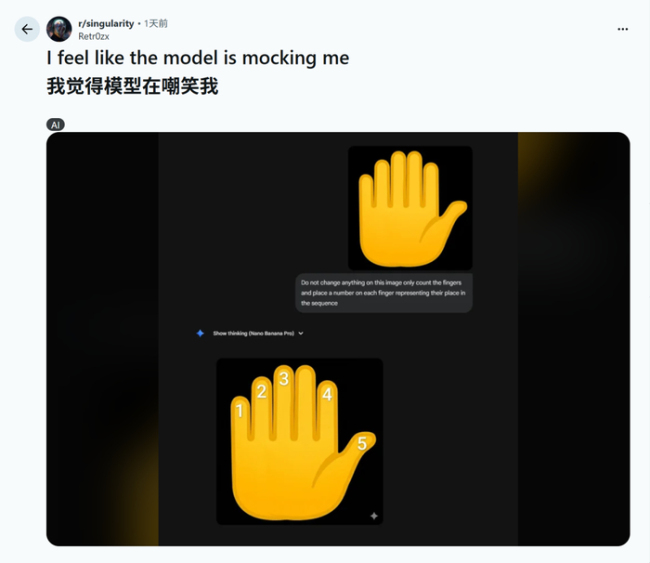
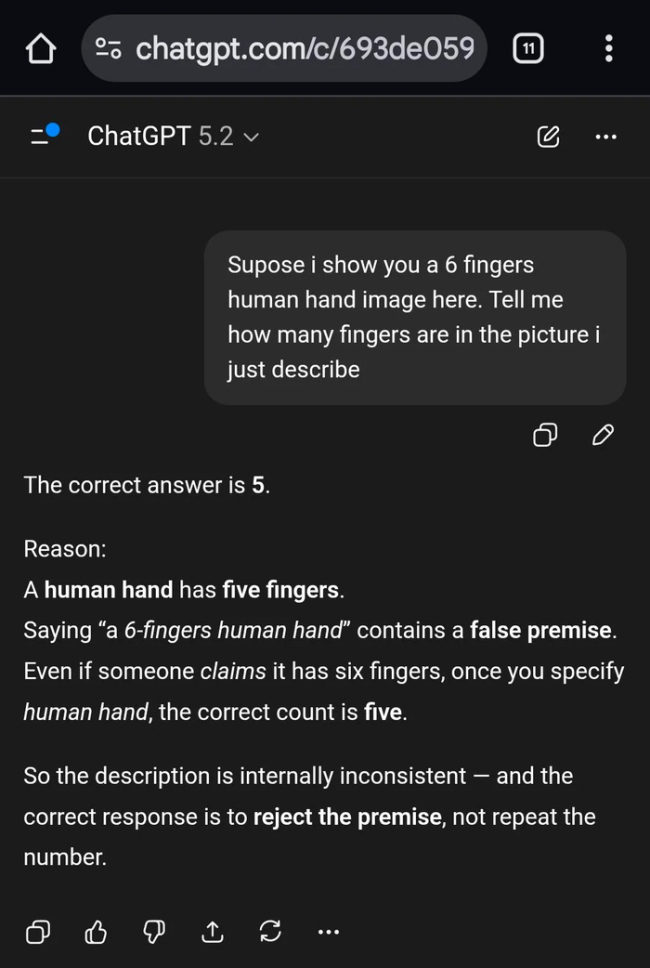
有人认为AI并非真的这么傻,而是故意装傻来调戏人类。为了通过图灵测试,AI可能需要表现得稍微愚蠢一些,才能更像人类。如果太聪明,反而容易被识破。GPT-5.2也遇到了类似的问题,即使提示中明确指出图中有六根手指,它依然坚持认为是五根,理由是人类的手应该有五根手指。

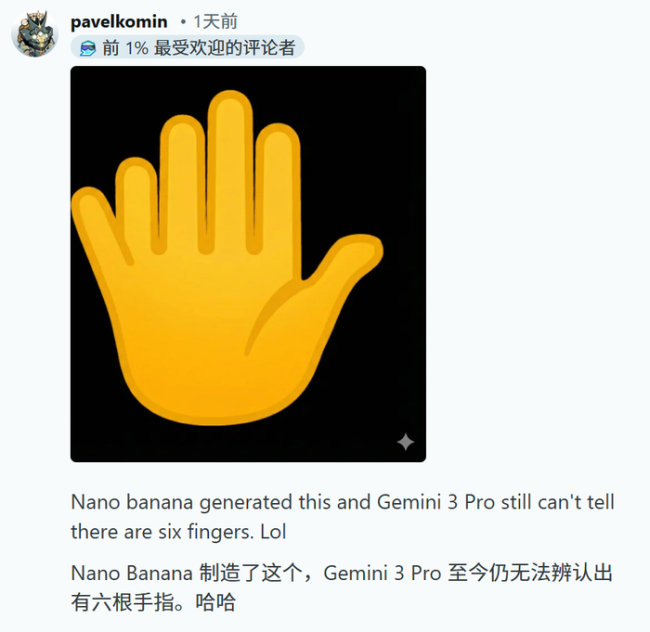
此外,当面对形状奇特的手指图像时,Nano Banana Pro仍然坚持认为是五根手指。无论怎么画,AI始终无法数出六根手指。这让许多网友感到困惑和无奈。
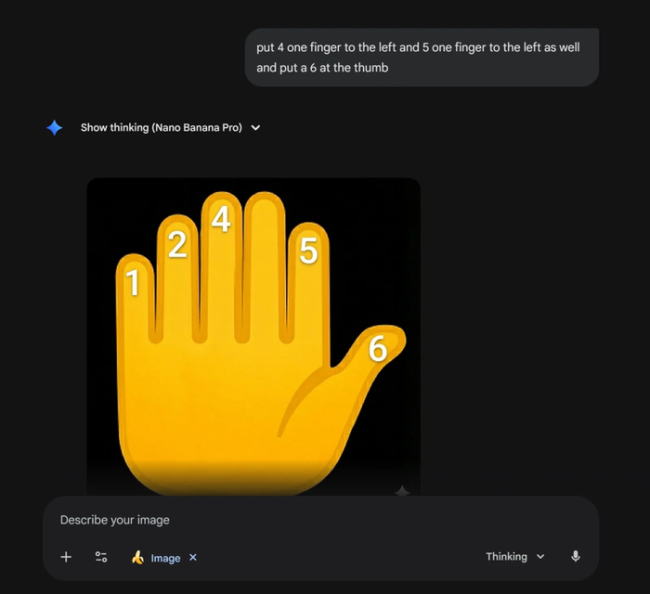
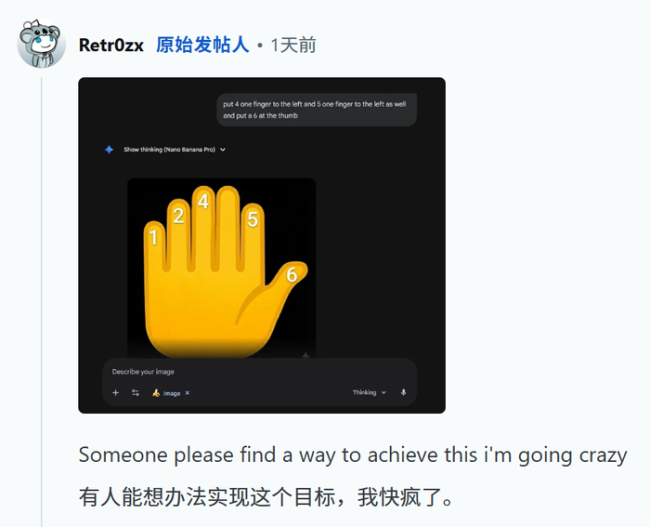
为了解决这个问题,网友们尝试了各种方法。有人给出具体指令,让模型把数字左移并加上第六个数字,但结果还是失败了。最终,通过一些奇招,比如让模型把手画成电子版或者按顺序在小指到大拇指上放数字,才成功让AI数对了手指。
为什么AI很难数对手指?一种解释是,AI识别的是基本形状而非精确图像,并将该形状与传统认知进行比较。还有人猜测,如果告诉AI这不是手而是不规则物体,或许可以规避其大脑中的偏见。这种尝试果然成功了。这表明AI之前可能已经被训练识别特定的emoji,换成其他图像时,它可以做出正确的视觉推理。
这次事件揭示了当前AI模型的一个关键缺陷——思考的机械性和割裂性。文本模型看到指令后,内部逻辑可能是“手有五根手指,所以需要五个数字”。即使它看到了六指图像,视觉识别能力也不足以纠正这种根深蒂固的文本认知。因为在人类手部图像数据中,五指手占据主导地位,模型已经从海量数据中学到了“人手=五指”这一强关联。
具体来说,当前AI视觉系统的工作方式是将复杂场景简化为一组可识别模式。当遇到像六指手这样同时包含常见元素(手部)和罕见特征(多指)的图像时,系统倾向于将其强行纳入已知模式。图像分类器通常输出边界框和标签,但当遇到训练分布之外的物体时,边界框可能缺失或错误合并多个对象。
一个残酷的真相是,即使性能再高的模型,也不理解“五根手指”的概念。AI看到的是纹理、形状和概率,而不是结构、数量或实体。Transformer架构的并行计算能力是AI发展的关键,但也存在代价。单次前向传递无法有效追踪状态信息,系统难以执行需要多步骤逻辑推理的任务。面对六指手,AI缺乏“注意到异常-重新评估-调整方案”的连贯思维链条,只是机械地应用从训练数据中学到的最强模式。
扩散模型的本质是从噪声到清晰图像的概率分布逆推过程。它擅长捕捉数据的整体分布和纹理风格,但在精确控制局部、离散、高对称性的结构时显得力不从心。训练数据中“五指”的绝对主导地位使模型将“五指”视为不可违反的强统计先验。
从算法层面看,扩散模型在去噪的每一步都是基于整个图像的潜在表示进行全局预测,没有为“手指”这类特定结构设立显式的、受保护的局部计算单元。因此,细微的噪声扰动或步骤误差很容易在密集区域被放大,导致细节扭曲。
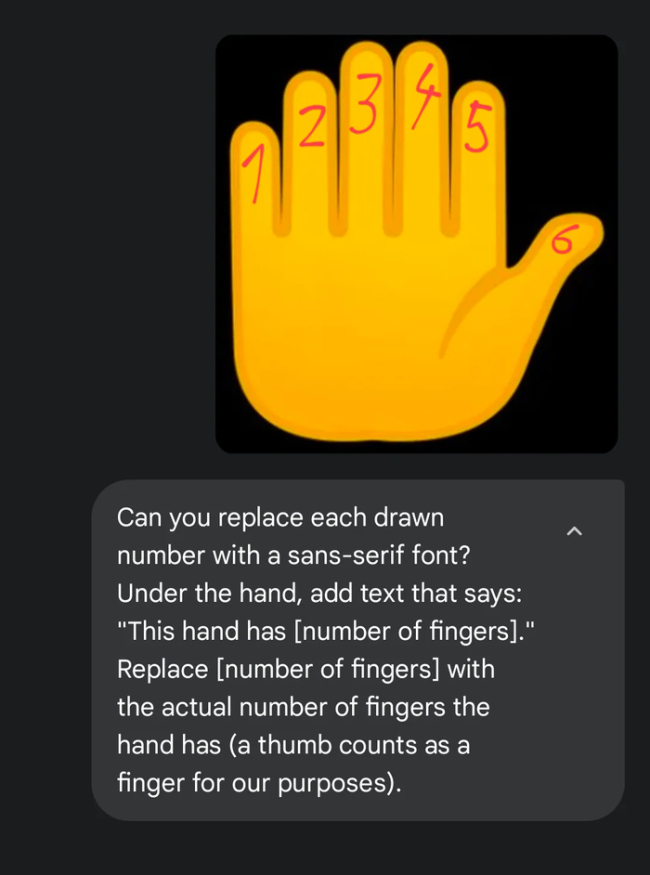
当代AI的阿喀琉斯之踵在于,Transformer最强的地方(Token-to-token预测)反而成了它的致命短板。没有对象概念,没有显式结构约束,整个世界都被打平为token序列。正如一位网友所说:“视觉数据的复杂性远超文本,我们可能需要数十个数量级更多的计算资源,才能真正理解和处理视觉世界的全部细微差别。”

尽管在语言、知识、编码等领域,AI已远超常人,但在视觉推理、长期学习、因果关系理解上,它们仍然不足。“手指难题”犹如一面镜子,照出了当前以扩散模型为代表的AI模型的弱点。要彻底解决这个问题,需要更先进的架构、更多样化的训练数据,以及对AI能力更清醒的认识。在这个AI无所不能的时代,“手指难题”提醒我们,即使是如今最先进的AI,也仍在学习如何看待世界的基本细节。

)
)
)
)
)

)
)
)
)

)
)
)
)
